Im Beispiel wird ein aus einer Datei einzulesender Text nach einem Muster
(Zeichen, Wort oder Satzteil)Ādurchsucht. Dabei kommen verschiedene Algorithmen zur Anwendung.
Das Muster Strategie wird verwendet, um während des Programmlaufs den
Algorithmus ändern zu können, ohne die Klasse, die den Text enthält, zu ändern.
Der Suchalgorithmus soll unanbhängig vom Text entwickelt und gewartet werden
können. Wenn ein oder sogar mehrere Algorithmen in der Klasse Text enthalten
sind, würde diese unnötig spezialisiert und komplex werden.
Deshalb sieht das Muster Strategie eine Teilung vor: Ein Text-Objekt
enthält nicht den Algorithmus selbst, sondern nur eine Referenz auf ein Objekt,
das die Suche ausführen kann. Dieses Objekt, Strategie genannt, implementiert
eine abstrakte Klasse, im Beispiel Textsucher. Sobald ein Text aufgeforsert
wird, nach einem Muster zu suchen, wird diese Aufgabe an die Strategie
delegiert. Die Auswahl des Algorithmus ist bei Erstellung des Text-Objektes
vorzunehmen, eine Änderung während der Lebenszeit des Text-Objektes ist
ebenfalls möglich.
Alternativ zu diesem Ansatz könnte man alle benötigten Algorithmen in der
Klasse Text vorrätig halten oder in einer Klassenhierarchie mehrere Unterklassen
von Text bilden, wobei jede Klasse einen Algorithmus impementiert.
Ein weiterer Grund für die Benutzung dieses Musters ist, neben den bereits
oben genannten, dass die Algorithmen Daten verwenden könnten, die mit der
eigentlichen Klasse Text nichts zu tun haben. Man verwendet dann das
Strategiemuster, um algorithmenspezifische Datenstrukturen zu verbergen.
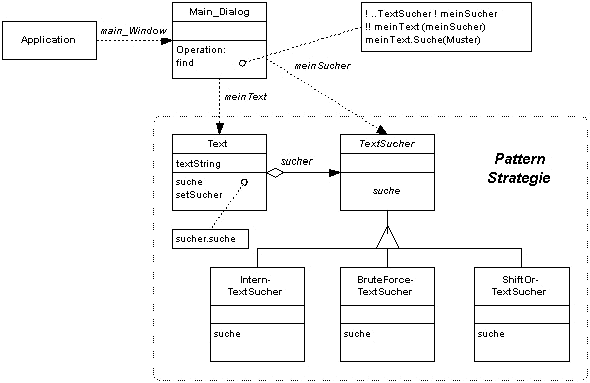
Das Beispiel ist wie folgt aufgebaut: In der Klasse App
wird ein Objekt der Klasse Main_Dialog erzeugt, dass die Oberfläche für den
Benutzer des Programms darstellt. Sie erlaubt die Auswahl einer zu
durchsuchenden Datei und die Eingabe eines Musters, nach dem gesucht werden
soll. Nach Aktivierung der Suchfunktion wird in der Methode find ein
Objekt der Klasse Text erzeugt. Diesem wird bei der
Erstellung der aus der Datei gelesene Text (String) sowie der erste der
Suchalgorithmen übergeben.
Alle Suchalgorithmen stellen Impementationen der abstrakten Klasse
Textsucher dar. Textsucher hat nur eine abstrakte
Methode suche, die von den drei Unterklassen InternTextSucher,
BruteForceTextSucher und
ShiftOrTextSucher definiert wird. Sie
können Näheres zu den 3 Algorithmen erfahren.
|
|
Abb. 1: Die Struktur des Beispiels |
Nachdem der erste Algorithmus sein Ergebnis, die Stelle an der das Muster gefunden wurde, zurückgeliefert hat, wird die Strategie, also der Algorithmus geändert. So erfolgt das Durchsuchen nach den verschiedenen Algorithmen. Die Ergebnisse werden jeweils dargestellt.
Auf eine Besonderheit sei an dieser Stelle noch hingewiesen. Da die unterschiedlichen Strategien unterschiedliche Daten des Textes erfordern, wird neben dem Muster auch eine Referenz auf den Text an die Suchalgorithmen übergeben.
Die Nachteile des Strategiemusters sollen auch nicht verschweigen werden. Die Klienten der Text-Objekte, in diesem Fall der Haupt-Dialog, müssen um die unterschiedlichen Strategien wissen, bzw. diese selber erzeugen. Dies bedeutet, das die Unterschiede zwischen den Strategien bekannt sein müssen, um eine passende Strategie auszuwählen. Somit kann es ein, dass die Klienten über Implementaionsaspekte Bescheid wissen müssen. Es ist ebenfalls offensichtlich, dass das Muster zu einer erhöhten Anzahl von Objekten führt, was bei einer erhöhten Flexibilität jedoch zu verschmerzen ist.

|
|
Abb. 2: Screenshot des Beispiels |
Gepackte Ausführbare Datei für Windows 95/NT:ĀStrategie.zip